Sponsored by Vercator
Lidar applications have rapidly expanded across industries. In part, this has been enabled by advances in registration algorithms that have simplified the creation of reality capture datasets. However, the inclusion of lidar capabilities of Apple’s latest hardware is a good example of how widespread this technology has become.
While point cloud data contains vast amounts of spatial detail, that data isn't yet being used to its fullest. There is still a gap between generating point clouds and extracting data from them — a critical step for applying this data in real-world applications. The ability to drill down to individual components will create better and more detailed 3D models for use in all kinds of scenarios. This is what lidar data segmentation or classification is all about — and automating that classification process is the key to widespread adoption. Let’s explain.
What is lidar data classification?
Data classification is the critical process of assigning values and meaning to data points within a point cloud. It's fundamentally the assignment of objects (and object characteristics) within point cloud data sets.
Why is data classification so important? Let's look at some examples:
- In construction: You could detect building components automatically from your scan and help track progress, assess material needs, and detect safety risks.
- In planning: You could create detailed urban inventories to develop and maintain smart city and digital twin models.
- In environmental science: You could monitor large scale geological trends and drill down even to tree species detection and density estimates.
All this can be made possible when clusters of lidar points have a class or tag assigned to them that defines the object type. Most commonly, you can classify lidar scans into several categories, often defined from the aerial capture domain such as bare earth or ground, vegetation, and water.
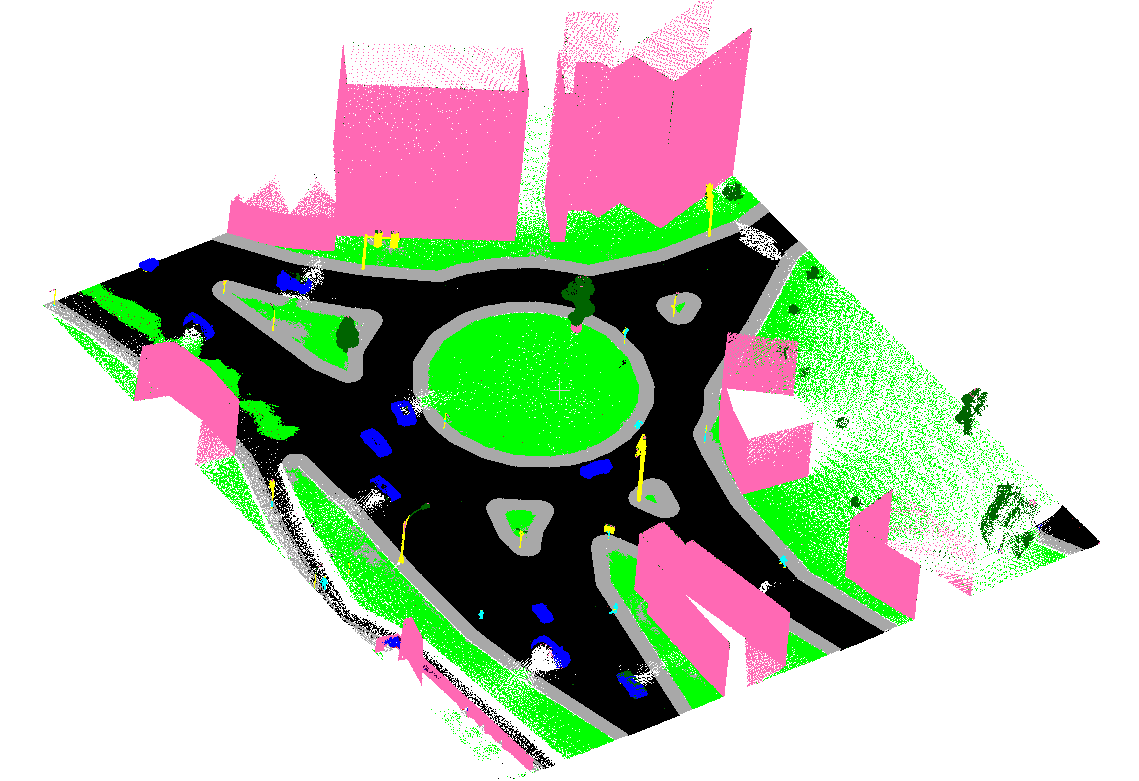
The American Society for Photogrammetry and Remote Sensing (ASPRS) has defined classification codes for LAS formats. The different classes are defined using numeric integer codes in the LAS files. This is a valuable set of standards, but manual processes to generate this data are simply too time-consuming to be deployed with real impact.
Manual vs automated lidar data classification
Point clouds require analysis to obtain information about contained objects and spatial properties. However, point clouds are challenging to classify automatically. To better understand "classification", it may help to think of it as labelling or annotation. It’s a question of who does the labelling, how fast they can do it, and how accurate it is.
There are four different ways that lidar data classification can occur, and the process of automating data classification is progressing through these multiple stages. Realistically, the best technology on the market sits somewhere within the second stage of the journey towards automation.
Stage 1: Manual
Traditionally, data classification has been carried out manually — assessing point clouds and assigning point clusters with classification categories, possibly with some user guided automation. You are manually working with point clouds and carrying out tasks repeatedly. No matter how often you mark similar objects like a road, you will always have to do it again. In some cases you get the chance to semi-automate repeated tasks but the quality is largely based on human interpretation and skill, so a high level of certainty of quality can be achieved but with a large time cost.
Stage 2: Cross-checked teaching
As we move towards the application of AI/ML, algorithms can deliver a first-pass at classification, which surveyors then manually quality check for accuracy. The algorithm removes the need for cross-checks during processing and limits the need to set too many classification parameters. Just as importantly, this type of automated classification can use manual inputs to improve an AL/ML algorithm, helping teach the software how to upgrade outcomes. With cross-checked processes, the burden of work on the user shifts from the data labelling task to the quality checking.
Stage 3: Automated verification
As classification algorithms improve, not every classification assignment needs cross-check verification. So, probability assignment can be made for each classification, and parameters set to generate cross-check reviews based on the level of certainty — for example, anything under a set accuracy. Your ability to set different levels of certainty enables users to trade speed for accuracy depending on the nature of the project.
Automated verification systems need to be flexible and fast. Realistically, the amount of manual cross-checking required will vary by project specification and the complexity (or novelty) of the data being analysed. However, like with “cross-checked teaching”, automated verification uses human input to further refine and train the result — helping reduce long-term manual requirements for effective point cloud data classification.
Stage 4: Fully automated
The moon-shot goal of training data classification algorithms is a fully automated system. Realistically, this is simply an improved version of automated verification that is good enough to confidently assign classifications without need for verification. However, the quality assurance of confidence assessments (and the possibility of manual review) would remain in any quality automated lidar classification software as a user will need a way to build trust in the process.
The Vercator approach to point cloud classification
At Vercator, we've pioneered cloud-based automation within point cloud processing and are applying the same technology to improve classification. Our registration algorithms deliver a more robust registration and we have now turned our expertise to creating a process that simplifies classification with AI.
In registration, we have developed these algorithms to simplify and accelerate the combination of multiple data sets, for example, combining mobile scan data outputs with traditional point cloud data sets. The defining components of our approach are:
- Unique algorithm processing: Extrapolating directional vectors from data while still retaining its unique and identifying characteristics allows for smarter, robust processing.
- Cloud-ready processing: Vercator takes advantage of scalable computing power available in the cloud to process multiple scans simultaneously and rapidly accelerate processing time — a technique that can also be applied to classification in order to accelerate analysis.
The primary outcome is that Vercator innovation delivers a more powerful and flexible use of scan data. Even if you have a standard point cloud scan of an area, you can layer data sets, using millions of reference points to align that data. Integrating scan data with other data sets feeds the AI-based recognition of objects and makes classification outputs much more accurate.
Enabling outcomes with the right software
So, can surveyors trust automated point cloud classification?
The answer at this stage of its evolution is "trust but verify". Good automation software will help you understand certainty levels and direct users to cross-check specific issues. The technology is still developing. Although there may be more “hype” than “reality” at this point, we aren’t far off from highly automated classification workflows beyond the aerial domain — and there are already efficiency gains to be made by investing in the right software.
Choosing the right software is critical to outcomes you can trust. Any technology's success comes back to outcomes, and data classification (and automated classification) will improve results. By automating, you increase efficiency and bring down costs, enabling more opportunities and innovation. Watch this space as Vercator delivers more on this, there will be significant improvements throughout 2022.